TLDR;
OpenShift Virtualization lets you run virtual machines and containers on the same OpenShift platform. One control plane. One set of policies. Less moving parts to manage.
Use it when you need to keep important VMs online while you modernize. You keep the lights on today and prepare apps for a container future at your own pace.
Success starts with the basics. Size your cluster with real numbers. Pick the right storage class for each workload. Keep a clean image library with golden images and simple templates. Plan the network early so teams get the right IPs and DNS every time.
Performance comes from clear limits and requests. Give busy apps the resources they need, avoid noisy neighbors, and test live migration during normal maintenance windows so there are no surprises.
Security is built in. Use namespaces and roles to separate teams, store secrets correctly, and turn on encryption for data at rest and in flight. Log everything that matters so audits are painless.
Day two is where many teams win or lose. Patch OpenShift and guest OSs on a rhythm, back up both cluster objects and VM disks, and watch key signals like CPU, memory, storage latency, and packet drops. Share simple dashboards so everyone can see what good looks like.
High availability and disaster recovery need clear targets. Define RPO and RTO, choose zone or region patterns, and run real failover drills. Write the steps down and practice them.
When you migrate from platforms like VMware, start with discovery, run a small pilot, then move in waves. Keep rollback ready. Operate VMs and containers side by side until refactoring makes sense.
Do the above and you get predictable performance, faster changes, safer operations, and a steady path to lower cost over time. Ready to dive into roles, outcomes, and prereqs next?

Who Should Use OpenShift Virtualization
Roles:
- CIO and IT head who wants clarity and control
- Platform lead running OpenShift day to day
- VM admin moving workloads into OpenShift
- Network and storage owners who care about throughput and latency
- Security and compliance team that needs clean audit trails
- SRE and ops team responsible for uptime
- Application team that still runs some VMs while building containers
What You Will Get:
- A clear picture of how OpenShift Virtualization works
- Checklists you can use before you go live
- Simple patterns for storage, network, and security
- Tuning tips that prevent noisy neighbor issues
- Runbooks for backups, patching, and live migration
- A small but solid plan to migrate from existing platforms
What You Should Know First:
- Basic OpenShift skills such as projects, roles, and routes
- How your current VMs are sized and how they perform
- Your storage options and the classes you will expose to VMs
- Your network plan including IP ranges, DNS, and any need for SR-IOV
- How you will create and patch golden images and templates
- How you will back up both cluster objects and VM disks
- Which metrics matter to you and where you will see them
OpenShift Virtualization in One Minute
What It Is:
A way to run virtual machines and containers together on OpenShift. One platform. One control plane. Shared policy, security, and automation. Your teams manage both worlds with the same tools.
Why It Matters:
You keep current apps alive while you modernize. You avoid extra platforms to patch and license. You get consistent guardrails for every workload. You ship changes faster because the pipeline and policy are the same for VMs and containers.
When To Use It:
• You have critical VMs that must stay up while you refactor apps over time.
• You want a single place for compute, storage, and network operations.
• You need stronger governance across teams without slowing them down.
• You plan to reduce cost and complexity by retiring a separate hypervisor stack.
How It Works At a Glance:
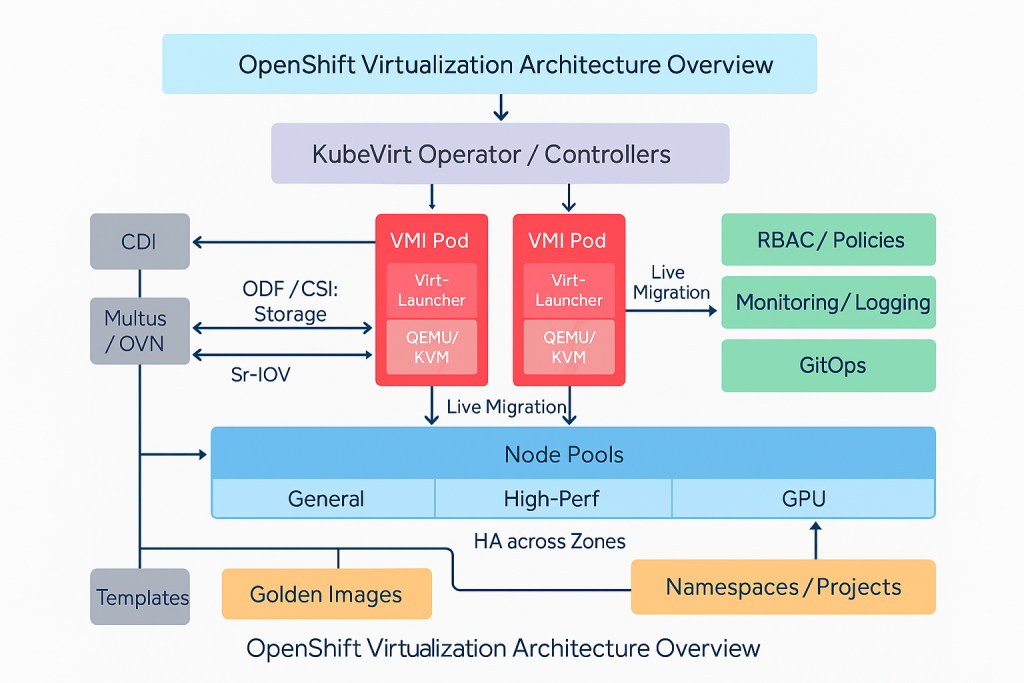
• KubeVirt adds VM capabilities to OpenShift.
• Containerized Data Importer handles images and disk moves.
• Multus and OVN handle primary and extra VM networks, with options for SR-IOV if you need line rate.
• OpenShift Data Foundation or any CSI storage serves the VM disks, snapshots, and clones.
• The same RBAC, quotas, and policies apply across everything.
What It Is:What a Good First Win Looks Like:
Pick two or three low risk VMs. Create a golden image. Launch VMs from a simple template. Test live migration during a maintenance window. Prove backup and restore. Share a small dashboard that shows CPU, memory, disk latency, and packet drops. When that is smooth, scale to the next wave.
To understand how this compares to traditional platforms, read our VMware vs OpenShift Virtualization comparison
Core Architecture
Control Plane and Kubevirt Pieces
OpenShift is the stage. KubeVirt brings virtual machine talent to that stage.
Key bits to know:
- The KubeVirt operator installs and upgrades the VM feature set for you.
- A Virtual Machine object describes the guest like CPU, memory, disks, and networks.
- A Virtual Machine Instance is the running thing on a node.
- The API stays native so you use the same tools and access model across the board.
VM Lifecycle Made Simple
You keep a tidy flow so work stays smooth.
- Build a golden image for each guest family like Windows Server or Rocky Linux.
- Store images in a trusted registry or image store.
- Use the Containerized Data Importer to pull in disks, convert formats, and clone quickly.
- Create templates so teams can launch a VM with sane defaults in minutes.
- Patch the golden image on a schedule and roll new VMs from it to keep drift low.
Storage That Matches the Workload
Pick storage like you pick tires for a car. The right set gives you grip and speed.
- OpenShift Data Foundation or any CSI provider can back VM disks.
- Use block for low latency databases and filesystems for general servers.
- Keep storage classes clear by intent such as performance, balanced, and capacity.
- Snapshots and clones speed up testing and shorten recovery time.
- Watch queue depth and latency so you see trouble before users do.
Networking Without Surprises
Give each VM the network it needs and nothing more.
- OVN K handles the primary network and gives you stable basics like IP and DNS.
- Multus adds extra networks when an app needs another lane.
- SR IOV is your fast lane for line rate and very low latency.
- Plan IP ranges and MAC pools up front so teams never collide.
- Put simple load balancing in place and document egress rules early.
Security and Compliance You Can Prove
Security is not an afterthought. It is part of the design.
- Use namespaces and roles to separate teams and apps.
- Apply security context constraints that fit the risk of each workload.
- Store secrets in the right place and enable encryption for data at rest and in transit.
- Turn on audit logs and forward them to your SIEM so reviews are calm and quick.
- Set quotas and limits so no one can starve a neighbor.
Key Concepts You Must Know
1) VM and Pod Basics
A virtual machine in OpenShift runs inside a pod. The scheduler still picks a node based on requests and limits. If you set clear requests, the VM gets a fair slice of CPU and memory. If you leave them empty, the VM fights for scraps and noisy neighbor issues show up.
Give each VM a small safety margin in memory. Add limits only when you have strong reasons. For CPU, start with requests that match normal load, then raise limits for short bursts.
2) Live Migration and Eviction
Live migration moves a running VM to another node with little pause. It is perfect for draining nodes during patch windows. Keep disks on shared storage that supports this move, test with a busy VM, and track how long the cutover takes.
Evictions happen when a node is unhealthy or under pressure. Protect important VMs with proper priority and disruption settings. Plan maintenance windows and migration policies so the platform can move guests without surprises.
3) High Availability Patterns
There are two layers. Platform HA keeps the cluster up. Workload HA keeps your app up.
For platform HA, run control plane across three zones if you have them. Keep at least three worker nodes in every zone that will host VMs. For workload HA, use multiple VM replicas where the app supports it, spread them across zones, and avoid shared single points like one writable disk.
If the app is not cluster aware, focus on fast restore and short cutover. Snapshots and clean boot scripts help a lot.
4) Devices and Acceleration
Some apps need direct access to a GPU or a fast network card. OpenShift can pass these devices through to the VM. Check that the node has the right hardware and drivers. Pin the VM to that node pool so the scheduler does not place it elsewhere. Keep a spare node with the same device for failover.
5) Node Roles and Placement
Use labels, taints, and tolerations to control where VMs land. Create a small pool for general VMs, another for heavy guests, and a third for devices like GPU. Add topology spread rules so replicas land in different zones. This keeps maintenance simple and limits blast radius.
Keep this set short and clear. Too many rules make scheduling slow and hard to reason about.
Planning and Readiness Checklist
Use this pre flight list before you run the first workloads. Keep it short, clear, and written down.
Capacity and Sizing
- List target VMs with CPU, memory, and disk needs.
- Add twenty percent headroom for growth and maintenance.
- Confirm worker counts per zone for fault tolerance.
- Validate storage throughput and latency for busy apps.
- Run a quick burn test to confirm numbers match reality.
Baseline and Service Goals
- Capture current CPU, memory, disk, and network stats for each app.
- Write simple service goals such as response time and error rate.
- Agree on acceptable maintenance windows.
- Record live migration time for a busy VM.
Image Strategy
- Create a golden image for each family such as Windows Server and popular Linux.
- Keep images in a trusted registry with version tags.
- Define a monthly patch cycle and a fast lane for urgent fixes.
- Build two or three clean VM templates per role such as web, app, and database.
Governance and Access
- Map teams to projects and roles.
- Set quotas for CPU, memory, and storage per project.
- Define naming rules for projects, VMs, networks, and disks.
- Store secrets correctly and rotate them on a schedule.
Network Plan
- Reserve IP ranges for primary and secondary networks.
- Decide on DNS, DHCP, and MAC pool rules.
- Mark apps that need SR IOV or direct device access.
- Document egress rules and load balancing choices.
Storage Plan
- Publish storage classes by intent such as performance, balanced, and capacity.
- Choose block for low latency databases and filesystem for general servers.
- Enable snapshots and clones for quick testing and recovery.
- Set alerts on latency and queue depth.
Backup and Restore
- Pick a tool set for cluster objects and VM disks.
- Test a full restore of one sample app.
- Define retention, locations, and encryption.
- Store runbooks and make them easy to find.
Observability
- Standardize metrics, logs, and events.
- Create a shared dashboard with CPU, memory, disk latency, and packet drops.
- Set alert rules with clear owners and actions.
- Review signals weekly and tune as needed.
Change and Patching
- Set a regular patch rhythm for OpenShift, KubeVirt, and guest OS.
- Use maintenance windows and test live migration during them.
- Keep a simple rollback plan for each change.
- Track changes and outcomes in one place.
Risk Review
- Identify top five risks such as capacity hot spots or single points.
- Write one control for each risk.
- Run a tabletop drill with the team.
- Fix gaps within the same week.
Pilot Exit Criteria
- Two or three VMs running from templates with backups verified.
- Live migration tested with clear timing.
- Alerts firing correctly and reaching the right people.
- Simple report that shows cost, performance, and stability trends.

Storage Best Practices
Profiles and Access Modes
Start with three simple classes by intent: performance, balanced, and capacity. Map each class to real hardware so teams know what they are getting. For busy databases, pick the fastest tier. For general servers, use balanced. For archives, choose capacity.
Pick the right access mode for the job. Use block volumes for low latency apps. Use filesystem volumes for most other servers. Keep the choice clear in templates so teams do not guess.
Filesystem Versus Block for VMs
Block gives tight control and low overhead. It shines for databases and heavy IO. Filesystem is flexible and easy to manage. It is perfect for web and app tiers. If you are unsure, start with filesystem and move a single test VM to block to compare numbers.
Snapshots, Clones, and Efficiency
Snapshots are your safety net before patching or risky changes. Clones speed up test environments and cut waiting time for teams. Use thin provisioning where it makes sense and watch real usage so you do not run the pool out of space. Set clean retention rules so storage does not bloat.
Disaster Recovery Basics
Decide your targets first. Write down the recovery point and recovery time you need. Choose regional sync for tight recovery or async copy for longer distances. Test a full restore of one real app, not just a sample VM. Keep runbooks short, clear, and easy to find.
Networking Best Practices
Multus Design
Think primary network first, extra networks second. Give every VM a clean primary network for basics like IP and DNS. Add a second or third network only when an app truly needs it. Keep names simple and consistent so teams launch the right one without guessing.
Plan network intent up front. One network for general traffic, one for storage if required, one for backups if your policy calls for it. Write this down in the templates so the right interface appears by default.
High Performance Paths with Single Root I/O Virtualization
Some apps need near line rate. For those, place them on nodes that have the right network cards and drivers. Create a small node pool for this purpose and keep a spare node ready for failover. Pin those VMs to that pool so the scheduler does not move them to slower hardware.
Measure before and after. Record baseline throughput and latency, then verify the gains once the VM runs on the fast path.
Ingress, Egress, and Load Balancing
Decide how traffic enters and leaves on day one. Internal only apps can stay behind service VIPs. Public facing apps should use a stable entry with a load balancer and clear TLS rules. For egress, document what can go out and where. Tight rules reduce risk and make audits easy.
If an app needs BGP or advanced routing, keep the change small and reversible. Test with one VM, then roll out to the rest.
IP Management and Naming
Reserve IP ranges per project or environment so teams never collide. Keep DNS records short and predictable. If you use Dynamic Host Configuration Protocol (DHCP), make the lease plan clear so addresses do not jump around. Keep a small registry of MAC pools to prevent duplicates.
Day Two Checks
Create a simple dashboard that shows packet drops, retransmits, and latency for the key networks. Alert when any of those cross the line you set. Review these signals weekly so small issues never become big ones.
Compute And Performance Tuning
CPU Planning
Give each VM clear requests so the scheduler can place it on the right node. Start with requests that match normal load, not peak. Add a small buffer and review after a week of metrics.
If a workload is latency sensitive, dedicate CPU to it on a small pool of nodes. Keep one spare node in that pool for failover.
Memory Sizing
Set memory based on real use, not a guess. Watch working set and swap inside the guest. Leave a little headroom so live migration and short spikes do not hurt.
Use large memory pages only for guests that benefit from them, such as heavy databases, and keep that choice in the template so it is repeatable.
Disk Performance
Pick the storage class that fits the job. Low latency class for databases, balanced class for app and web, capacity class for archives.
Track queue depth, read and write latency, and throughput. If numbers drift, check noisy neighbors, then move the VM to a faster class or spread load across more disks.
Prefer paravirtual drivers in the guest and keep them updated.
Network Performance
Record a baseline for throughput and latency before you go live. Use an extra network for backup or storage traffic when needed so it does not fight with app traffic.
For near line rate, place the VM on nodes with the right network cards and drivers, and keep a twin node ready for failover. Verify with a simple before and after test.
Live Migration Timing
Measure how long a busy VM takes to move during a maintenance window. Note the pause time the app sees. If it is too long, reduce write pressure on the disk, add a little memory, or schedule the move during a quieter period.
Keep a short policy for when the platform can move VMs and when it must wait.
Noisy Neighbor Control
Set limits only where needed. Use fair requests for everyone. If one VM still causes trouble, place it on a separate pool or raise its request so the scheduler gives it space.
Review top talkers for CPU, memory, disk, and network each week and adjust templates rather than one off fixes.

Security, Isolation, And Compliance
Clear Boundaries With Projects and Roles
Put each team in its own project. Use role based access so people only see what they need. Give view rights by default and add edit rights when required. Keep admin rights small and short lived.
Guardrails for Workloads
Use security context constraints that match the risk of each app. Keep the default tight and relax only when a real need appears. Run SELinux in enforcing mode. Use seccomp and drop extra capabilities unless a guest truly needs them.
Secrets and Keys
Store secrets in the platform. Rotate them on a schedule. Use a key management service for encryption keys. Do not bake secrets into images or templates. For shared items, use a sealed secret flow so only the cluster can read it.
Data Protection
Turn on encryption at rest for storage. Use TLS for traffic inside the cluster and at the edge. For sensitive apps, require mutual TLS between services. Document which storage classes meet your data rules.
Audit and Logging
Send audit logs and workload logs to your central system. Keep a simple map that shows which logs prove each control. Review a small sample every week so you catch gaps early. Keep time sync healthy across nodes so records line up.
Quotas and Limits
Set fair quotas for CPU, memory, and storage per project. Add request defaults in templates so teams start with good values. This keeps neighbors safe and makes costs clear.
Evidence You Can Show
Write short policies and keep them in version control. Save reports from backups, patch runs, and failover drills. Keep a checklist for each release that shows tests passed and approvals given. This makes audits calm and fast.
Day Two Operations
Patching That Never Surprises You
- Keep a simple calendar for OpenShift, KubeVirt, and guest OS updates.
- Use a small canary group first, then roll out to the rest.
- Drain nodes during a quiet window and test live migration while traffic is light.
- Record what changed and how long it took, then update the runbook.
Backups You Can Trust
- Protect both cluster objects and VM disks.
- Run a daily job for fast recoveries and a weekly full job for deep safety.
- Restore a real app once a month and write down the exact steps.
- Encrypt backup data and keep copies in a second location.
Clear Eyes on Health
- Share a single dashboard with CPU, memory, disk latency, and packet drops.
- Alert on trends, not just spikes, so you catch slow drift.
- Tag every alert with an owner and a first action to take.
- Review signals every week and prune noisy alerts.
Cost and Capacity Checks
- Track requests versus real use by project and by team.
- Right size busy VMs and nudge idle ones down.
- Publish simple reports so teams see the impact of their choices.
- Set soft limits and agree on who approves changes.
Change Flow That Scales
- Keep VM templates, network defs, and policies in git.
- Use small pull requests and short reviews.
- Roll forward when you can and keep a short rollback note for the rare case you cannot.
- Tag each release so you can trace what is running.
Incident Basics
- Write a short playbook for the top five issues you see.
- During an event, log the timeline as you go.
- Afterward, capture one fix for the root cause and one guardrail to prevent repeat pain.
- Share lessons in a short note with screenshots.
Team Rhythm
- A 15 minute weekly check for patches, alerts, and open risks.
- A monthly drill that restores one app and runs one live migration.
- A quarterly cleanup that retires old images and updates templates.
- A half day review twice a year to recheck capacity and DR targets.
High Availability And Disaster Recovery
What Stays up and What Comes Back
Think of availability in two layers. The platform layer keeps OpenShift healthy. The workload layer keeps your app serving users. You need both.
Platform HA in Simple Terms
Spread control plane nodes across three zones if you have them. Keep at least three worker nodes in every zone that will host VMs. Use even power and cooling across racks so one hiccup does not take out a whole slice of capacity. Test node drains and watch live migration handle the move without a fuss.
Workload HA That Actually Works
If the app supports active active, run two or more VM replicas and place them in different zones. Keep replicas on separate storage and network paths where possible. If the app is single instance only, focus on fast restart: clean boot scripts, recent snapshots, and a known good image.
Clear Targets
Write down two numbers for each app. How much data can you afford to lose, even in a bad day. How long can the app be down before it hurts the business. Those two numbers guide every design call you make.
Patterns by Need
Zone level resilience for most apps: multiple worker nodes per zone and replicas spread out.
Region level resilience for strict uptime needs: async copy to another region and a small standby footprint you can scale up during failover.
Cold standby for low priority apps: backups only and a simple restore runbook.
Storage Choices That Help Recovery
Pick storage classes by intent. Use fast tiers for databases that need tight recovery time. Turn on snapshots for quick rollbacks. Use replication or remote copy for apps with strict targets. Keep retention rules tidy so storage does not grow without limit.
Network Basics for HA and DR
Reserve subnets in both primary and recovery sites. Decide how you will switch traffic during failover: DNS cutover, VIP move, or load balancer policy. Keep the steps short and repeatable. Practice them.
Runbooks You Can Trust
Write the steps when you are calm, not during an outage. Keep each runbook short enough to fit on one page. Include who does what, the exact commands, and the checkpoints that prove progress.
Drills That Build Confidence
Practice small and often. Move a non critical VM during a quiet window and time the pause. Restore a real app from last night’s backup. Once a quarter, run a full failover of one service and then fail back. Save the timings and the lessons.
Signals to Watch
Track migration time, pause time, recovery time, and data lag for async copies. Alert when any of these drift beyond your targets. Review after each drill and update the plan.

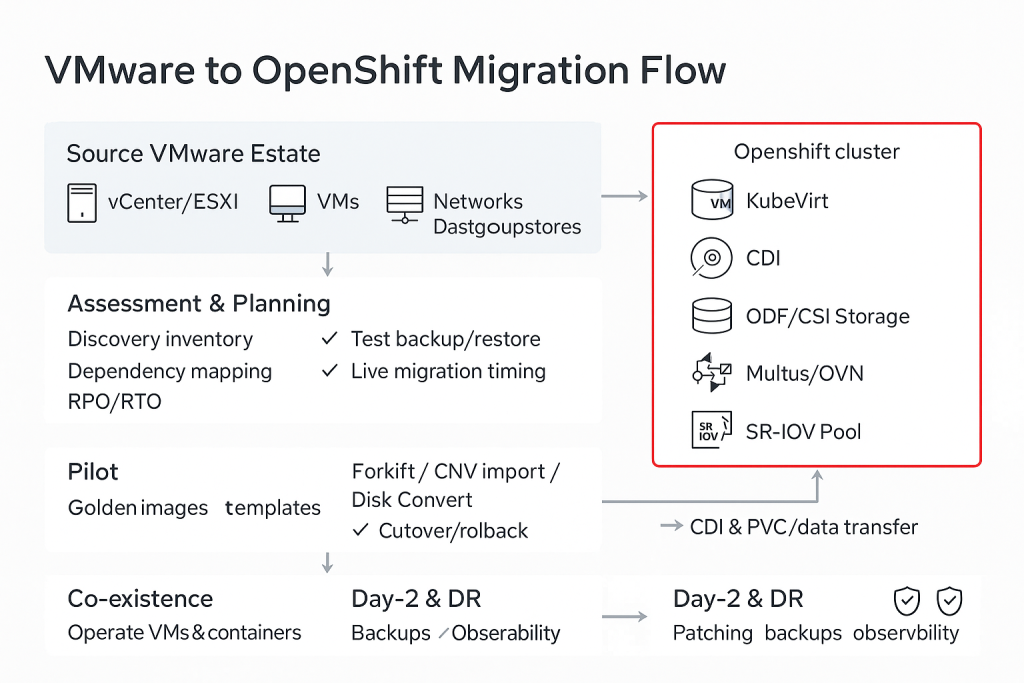
Migration To OpenShift Virtualization
Discovery and Assessment
Start with a clear picture of what you have today.
- List every VM with CPU, memory, disk, network, and OS details.
- Note uptime needs, maintenance windows, and any licensing quirks.
- Group VMs by affinity such as app tiers and shared databases.
- Capture baseline numbers for performance and user traffic.
- Mark quick wins that are low risk and high confidence.
Pilot That Proves the Path
Pick two or three VMs that represent common patterns.
- Build a golden image for the guest family.
- Create a simple template for each VM role.
- Import disks with the data importer and verify boot.
- Test backups, restore, and live migration during a quiet window.
- Share a small dashboard with CPU, memory, disk latency, and packet drops.
A good pilot ends with a short report that shows results, gaps, and next steps.
Migration Methods
You have a few practical ways to move.
- Direct import for images that already match the target format.
- Convert and import for guests that need disk or driver changes.
- Forklift style tools for larger batches with mapping and cutover help.
- Rebuild from template for simple guests where a fresh start is faster.
Choose the method per wave. Do not force one path for every case.
Wave Based Cutover With Rollback
Move in small waves so change stays safe and steady.
- Define a wave by app, environment, or site.
- For each wave, write entry and exit checks such as health, backup, and alert readiness.
- Schedule cutover in a known window and keep owners on call.
- Measure user impact and roll forward when numbers look good.
- Keep a written rollback that returns traffic and data to the source if needed.
Co Existence with Containers
You do not need to refactor on day one.
- Run VMs and containers side by side on the same platform.
- Put policy, access, and observability in one place so teams learn one way of working.
- As confidence grows, pick one candidate service to containerize and measure the gain.
- Repeat when it makes business sense, not before.
Hand-off to Operations
Close each wave with simple tasks that keep things calm.
- Update runbooks, templates, and images with lessons learned.
- Tune requests and limits based on real use.
- Right size storage classes where performance needs changed.
- Share a short note with outcomes, costs, and next actions.
Operating At Scale
GitOps for VM Definitions and Policy
Put VM specs, network objects, and guardrails in git. Treat them like code. Every change becomes a pull request. Reviews stay short, focused, and visible. Rollouts are easy to track and just as easy to roll back. This habit brings order as teams and clusters grow.
Golden Image Factory
Create a simple pipeline that bakes, scans, and signs images. Tag by version and date so anyone can trace what is running. Patch on a schedule and keep a fast lane for urgent fixes. Retire old images each quarter to prevent drift. The goal is boring, predictable images that launch the same way every time.
Templates That Scale With You
Offer a tiny set of clean templates mapped to common roles such as web, app, and database. Each template sets requests, storage class, and networks. When you learn something new, update the template once and everyone benefits.
Multi Tenant Guardrails
Group teams by project. Apply fair quotas for CPU, memory, and storage. Add request defaults so good behavior is automatic. Give view rights by default and time bound admin rights when needed. This keeps neighbors safe without slowing anyone down.
Shared Services Done Right
Centralize backups, logging, and metrics. Publish one dashboard that shows the signals leaders care about. Add tags for team and environment so you can slice cost and health by owner. Fewer tools, clearer pictures.
Region and Zone Growth
As usage expands, spread worker pools across zones. Keep capacity even so a single rack or room issue never causes churn. For new regions, start small with a pilot footprint, then scale once you trust the numbers.
Release Rhythm
Set a weekly window for small changes and a monthly window for larger moves. Use canaries first, then roll out in waves. Capture timings and outcomes in one short note. Over time this rhythm removes fear from change.
Budget Clarity
Track requests versus real use by team. Share a plain report that highlights idle guests and hot spots. Nudge owners to right size. Celebrate teams that improve efficiency. Cost control becomes a shared habit, not a surprise at quarter end.
Common Pitfalls And How To Avoid Them
-
Skipping Real Sizing
Teams copy old VM specs without checking live use.
Fix: Measure CPU, memory, disk, and network for a week. Set requests to match normal load with a small buffer.
-
One Storage Class for Everything
A single class tries to serve databases and file servers alike.
Fix: Publish three clear classes by intent: performance, balanced, and capacity. Map each to real hardware.
-
No Golden Images
Random ISOs and ad-hoc builds lead to drift and slow patching.
Fix: Keep a small image library. Patch monthly. Tag and sign every image.
-
Templates That Hide Key Choices
Teams guess at networks, storage, and requests.
Fix: Put sane defaults in templates. Choose the network, storage class, and starting requests for each role.
-
Live Migration Untested
Moves work on paper but stall on busy nights.
Fix: Time a migration during a normal window. Record total time and pause time. Adjust memory and disk write rate if needed.
-
Backups That Miss Half the Stack
Only VM disks are protected, or only cluster objects.
Fix: Back up both. Test a full restore of one real app each month. Write down the exact steps.
-
Weak Network Plan
IP ranges collide. DNS names are inconsistent.
Fix: Reserve ranges per project. Keep short, predictable names. Document egress rules and load balancing from day one.
-
Loose Access Control
Everyone gets admin to make things “easy.”
Fix: Give view by default. Grant edit by role. Time-box admin rights. Review access every month.
-
Ignoring Noisy Neighbors
A few heavy guests slow the rest.
Fix: Set requests for all VMs. Move the top talkers to a small pool or raise their requests so the scheduler places them well.
-
Alerts That Shout Without Meaning
Too many alerts or none at all.
Fix: Start with four signals: CPU, memory, disk latency, packet drops. Add owners and first actions. Tune weekly.
-
DR Targets Not Written
People talk about RPO and RTO but never agree on numbers.
Fix: Write two numbers per app. How much data can you lose. How long can you be down. Design to meet those numbers and drill them.
-
Change Notes Scattered
No one remembers what changed or why.
Fix: Put templates, policies, and network objects in git. Use short pull requests. Tag each release. Keep a one-page change log.
Many of these issues appear during early migration waves. Review our VMware Alternatives in 2025 analysis to see how enterprises are diversifying.
Reference Architectures
Small And Mid Size Team
- Think simple, steady, and easy to run.
Footprint
- Three control plane nodes
- Three to six worker nodes in one region
- One storage backend with two classes: balanced and capacity
Network
- One primary network for all VMs
- One extra network for backups if policy requires it
Storage
- Filesystem class for most servers
- Block class reserved for the one or two busy databases
Operations
- Weekly patch window
- Monthly backup restore drill for one real app
- Shared dashboard with four signals: CPU, memory, disk latency, packet drops
Why this works
- You get a stable base that is quick to patch and easy to observe. Teams launch from clean templates and grow without surprises.
Enterprise Multi Zone
Built for larger estates that want resilience within a region.
Footprint
- Three control plane nodes spread across three zones
- At least three worker nodes per zone for VM hosting
- Storage with three classes: performance, balanced, capacity
Network
- Primary network for app traffic
- Secondary network for storage or backup as needed
- SR IOV pool available for a few latency sensitive guests
Placement
- Topology spread rules so replicas land in different zones
- Taints and tolerations to keep heavy guests on their own pool
Operations
- Canary rollouts in one zone, then two more waves
- Quarterly live migration timing review
- Cost and capacity report per team
Why This Works
- You ride out single zone issues, keep fast apps fast, and still run a tidy platform with clear guardrails.
Regulated Sector with DR
Designed for banks, healthcare, and public sector teams that need proof on paper.
Footprint
- Primary region with three zones
- Recovery region with a smaller standby footprint
- Dedicated storage tiers for performance and for long term retention
Security and Governance
- Projects per team with role based access
- Encryption at rest and in transit with key management
- Audit and workload logs streaming to the central system
- Policies, templates, and runbooks in version control
Data Protection
- Nightly backups for VM disks and cluster objects
- Replication or async copy to the recovery region based on targets
- Signed golden images and a monthly image refresh
DR Plan
- Written RPO and RTO per app
- DNS or VIP failover steps that fit on one page
- Quarterly failover and failback drill with timings captured
Why This Works
- You meet strict targets, keep evidence tidy, and practice the moves often enough that teams stay calm during real events.
Checklists And Templates
Use these as drop-in pages for your runbooks and wikis. Keep them short, adjust names to match your teams, and share in one place everyone can find.
Readiness Checklist
-
VM list complete with CPU, memory, disk, and network needs
-
Storage classes published and mapped to real tiers
-
Network plan agreed with IP ranges, DNS, and any SR-IOV needs
-
Golden images built, scanned, and tagged
-
Templates created for web, app, and database roles
-
Backup plan covers cluster objects and VM disks
-
Baseline metrics captured for the pilot VMs
-
Access mapped: projects, roles, quotas
-
Maintenance window set and owners on call
-
Pilot exit criteria written and visible
If you’re preparing a full migration, our step-by-step How to Migrate from VMware to OpenShift guide covers discovery, pilot setup, and wave planning.
Go-Live Checklist
-
Health green on control plane and worker nodes
-
Storage latency within target during a burn test
-
Network checks pass for ingress, egress, and DNS
-
Backups run and one restore validated this week
-
Alerts configured with clear owners and first actions
-
Live migration timed on one busy VM
-
Templates locked and tagged for this release
-
Change note opened with scope and rollback steps
-
Stakeholders notified with a short timeline
-
Post-go-live review booked
DR Drill Script
-
State the app, its RPO and RTO, and the drill goal
-
Take a snapshot or confirm last backup time
-
Restore to a clean namespace or project
-
Switch traffic by DNS cutover or VIP move
-
Validate with a simple user journey and key metrics
-
Record recovery time and any data lag
-
Fail back using the same steps in reverse
-
Write two fixes: one for speed, one for clarity
-
Update the runbook and close the drill with timings
Golden Image Playbook
-
Pick base OS and harden it
-
Install common agents and paravirtual drivers
-
Apply updates, reboot, and recheck services
-
Scan, sign, and tag with version and date
-
Publish to the trusted registry
-
Note build steps in a small README
-
Review monthly and retire old tags
VM Template Checklist
-
Name and purpose clear in the template title
-
CPU and memory requests set to match normal load
-
Storage class chosen by role
-
Primary network set and any extra network listed
-
SSH or console access defined
-
Startup scripts added if needed
-
Labels and annotations applied for team and environment
-
Owner field filled so questions have a home
Backup and Restore Sheet
-
What is protected: objects, disks, or both
-
Schedule for daily and weekly jobs
-
Retention by app class
-
Encryption location and key rotation plan
-
Tested restore steps with commands and screenshots
-
Contact list for on-call and storage owner
Change Note Template
Title
Date and window
Scope in one paragraph
Steps to apply
Checks to confirm success
Rollback steps
Owner and reviewers
Metrics to watch during and after
Outcome and timings
Incident One-Pager
App and owner
What users saw
Start time and end time
User impact in plain words
Timeline of key events
Root cause in one line
Fix applied
Follow-ups with owners and dates
Screenshots or links
Cost and Capacity Report Outline
Team and project list
Requested versus used CPU, memory, and storage
Top idle VMs to right size
Top hot spots that need more headroom
Savings from last month’s actions
Next three actions with owners
Frequently Asked Question
Is OpenShift Virtualization a separate product?
No. It is a feature set that adds virtual machines to your OpenShift cluster through KubeVirt. You manage VMs and containers with the same tools.
Can I keep running my existing VMs while I modernize?
Yes. You can move selected VMs first, keep them stable, and refactor apps later at your own pace.
Do I need special hardware?
Standard x86 servers work well. For very low latency or GPUs you will want nodes with the right cards and drivers. Plan a small pool for those.
What storage should I pick for VM disks?
Use a fast class for databases, a balanced class for app and web tiers, and a capacity class for archives and test copies. Keep these choices clear in templates.
How are networks handled for VMs?
Every VM gets a primary network from OpenShift. If an app needs an extra network you can add it with Multus. For line rate you can use SR IOV on a dedicated node pool.
Can I live migrate a busy VM?
Yes. Keep disks on shared storage that supports live moves. Test during a normal maintenance window and record the pause time so there are no surprises.
How do I back up VMs?
Protect both cluster objects and VM disks. Run daily jobs for fast recovery and a weekly full job. Prove a restore each month with a real app.
What about security and compliance?
Use projects and roles to separate teams. Keep secrets in the platform. Turn on encryption at rest and in transit. Send logs to your central system and keep short evidence packs.
How many templates do I need?
Start with three. One for web, one for app, one for database. Each template sets requests, storage class, and networks. Expand only when a real need appears.
Will this replace my current hypervisor forever?
Maybe not on day one. Many teams run VMs on OpenShift for most apps and keep a small legacy footprint for corner cases. Over time that footprint can shrink.
What skills do my admins need?
Basic OpenShift skills plus a clear understanding of VM sizing, storage classes, and networks. A short runbook and a steady patch rhythm close the gaps fast.
How do I control costs?
Track requests versus real use by team. Right size hot spots, nudge idle guests down, and publish a simple monthly report so owners see the impact.
What is a good first pilot?
Pick two or three common VMs. Build a golden image. Launch from templates. Test backup, restore, and one live migration. Share a small dashboard with CPU, memory, disk latency, and packet drops.


