
TL;DR
OpenShift Virtualization lets you run VMs and containers on one OpenShift platform, powered by KubeVirt. It adds VM-specific resources to Kubernetes (CRDs) and runs each VM in a pod via virt-launcher with QEMU/KVM acceleration. You keep today’s VM workloads online while you modernize selectively, reuse GitOps/policy/observability, and enable live migration, multi-networking (Multus/SR-IOV), and CSI-backed snapshots/backup. For VMware exits, Red Hat’s Migration Toolkit for Virtualization (MTV) provides an opinionated, low-risk path to migrate vSphere VMs into OpenShift.
Introduction
Enterprises are consolidating platforms: instead of operating separate stacks for VMs and containers, teams increasingly standardize on OpenShift and add VM support with OpenShift Virtualization (KubeVirt). The result is one control plane for both workload types, consistent security and governance, and a cleaner VMware exit path without a risky “big bang” rewrite. Live migration supports maintenance and node evacuations; Multus and SR-IOV enable advanced networking; CSI unlocks snapshots/cloning/backup integrations. For vSphere shops, MTV handles discovery, mappings, and cutovers into OpenShift Virtualization.
What Is OpenShift Virtualization?
OpenShift Virtualization is Red Hat OpenShift’s built-in capability, powered by the open-source KubeVirt project, that lets you run virtual machines (VMs) and containers side-by-side on the same Kubernetes platform. Instead of managing separate stacks for VMs and containers, teams use one control plane for scheduling, networking, storage, security, and automation. This makes it possible to keep critical VMs online while modernizing at your own pace, apply the same GitOps and policy controls to both workloads, and gradually refactor or retire VMs without disrupting the business. In short, OpenShift Virtualization turns Kubernetes into a unified platform for today’s VM workloads and tomorrow’s cloud-native apps.
Why it matters:
- One platform: unified operations for VMs + containers
- Lower risk: migrate/host VMs without rewiring your toolchain
- Modern ops: GitOps, CI/CD, policy, and automation for all workloads
“OpenShift Virtualization (based on KubeVirt) lets enterprises run and manage VMs on Kubernetes, unifying VM and container operations under one OpenShift control plane.”
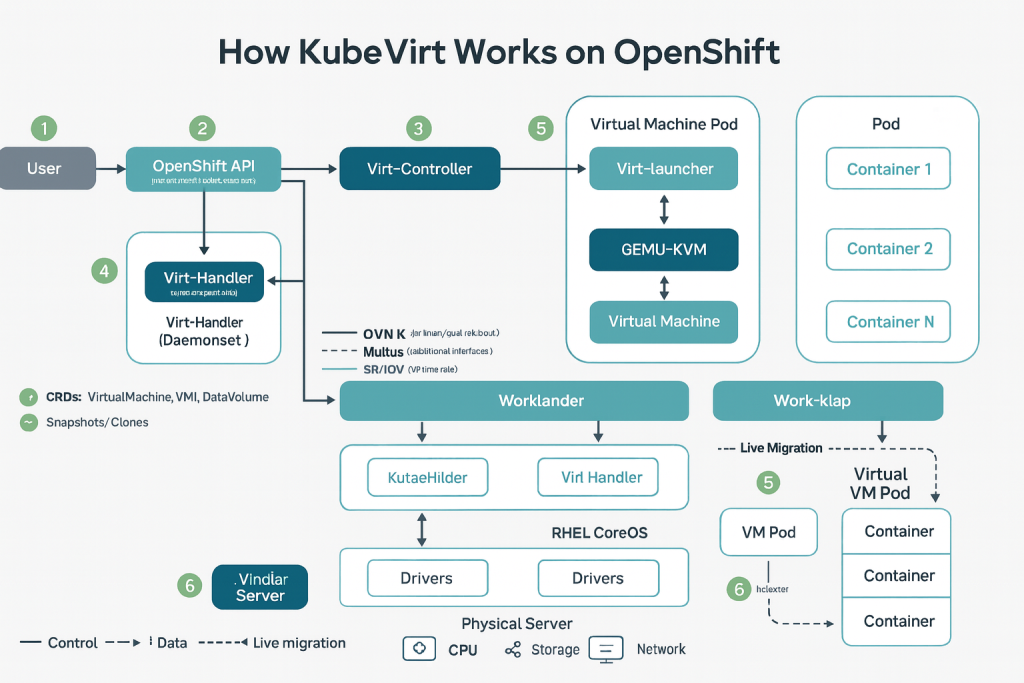
How KubeVirt Works on OpenShift
CRDs & Operators
KubeVirt adds CRDs (e.g., Virtual Machine, Virtual Machine Instance, DataVolume) so VMs become first-class Kubernetes resources. Operators handle lifecycle tasks (install/upgrade, health checks) the same way other OpenShift components do.
virt-launcher, QEMU/KVM, libvirt
Each VM runs inside a pod via a virt-launcher container that starts the VMI with QEMU/KVM acceleration on the host. This keeps isolation with cgroups/namespaces while giving you near-bare-metal performance characteristics typical of KVM.
Scheduling & Placement
VMs obey Kubernetes scheduling (taints/tolerations, node selectors, affinities). Use anti-affinity and topology spread to keep redundant VMs on different failure domains; combine with eviction strategies and live migration for maintenance windows.
Storage (CSI)
VM disks are PVCs backed by CSI drivers (Ceph/RBD, NetApp ONTAP, etc.). This enables snapshots, clones, and shared access modes when supported; live migration commonly requires shared RWX volumes.
Networking (OVN-K, Multus, SR-IOV)
OpenShift’s default OVN-Kubernetes provides primary pod networking. Multus CNI lets you attach multiple networks/NICs (e.g., mgmt + data). For high-performance paths, add SR-IOV (and the SR-IOV Network Operator) to expose VFs to VMs
Day-2 Tooling
Because VMs are Kubernetes resources, you can apply GitOps (Argo CD), policies/quotas, and existing observability pipelines to both VMs and containers simplifying operations and audits.
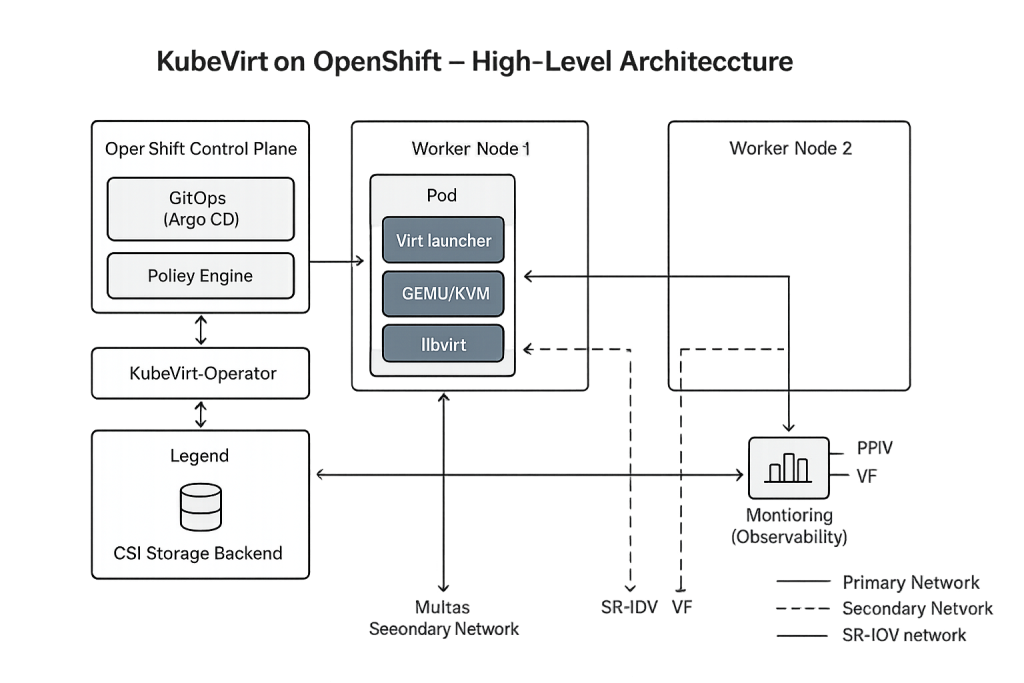
Architecture Blueprint
- Control plane: OpenShift API/etcd, Operators, KubeVirt Operator.
- Worker nodes: Run pods; each VM is hosted by a pod via virt-launcher which starts QEMU/KVM.
- Storage layer (CSI): Backing PVCs for VM disks; enable snapshots/clones and shared RWX when needed.
- Networking: OVN-K for default; Multus to attach additional networks; SR-IOV for near-line-rate.
- Mobility: Live migration between nodes for maintenance or balancing (subject to storage/network prerequisites).
- Migration into the platform: Migration Toolkit for Virtualization (MTV) for vSphere → OpenShift VM moves (assessment, mappings, orchestration).
Installing & Enabling OpenShift Virtualization
Prerequisites
- OpenShift cluster (cluster-admin access), compatible OCP version.
- Worker nodes with hardware virtualization (KVM) enabled.
- Storage class aligned to your needs (RWO for most, RWX for live migration).
- Networking plan (default OVN-K; Multus/SR-IOV if you need multi-NIC or line-rate).
- Change management & rollback window for enabling platform features.
Operator install (UI Path)
- In the OpenShift Console, go to Operators → Operator Hub and search OpenShift Virtualization.
- Click Install, accept defaults, then create the HyperConverged custom resource (keep the default name kubevirt-hyperconverged).
- Wait for the Operator and components to reconcile; confirm that the Virtualization section appears in the console.
Operator Install (CLI Gist)
- Apply the Operator subscription and then create the HyperConverged CR.
- Validate cluster operators (oc get co), CSV status, and CR conditions until Available=True.
Optional Add-ons You Might Enable Now
- Multus for multiple networks/NICs per VM (e.g., mgmt + data).
- SR-IOV Network Operator for performance-critical VFs and near line-rate I/O.
- Containerized Data Importer (CDI) for VM disk imports/clones/uploads via DataVolume.
Storage Notes (Live Migration Ready)
If you plan to live-migrate VMs between nodes, ensure the VM disks sit on shared storage with RWX (e.g., CephFS/RBD with RWX support, vendor RWX). Live migration also requires sufficient free RAM/bandwidth during node drains.

Creating & Operating VMs
Templates & First VM
- Use OpenShift’s VM templates (Linux/Windows) and customize vCPU, memory, disks, and NICs.
- For Windows VMs, install VirtIO drivers (and QEMU guest agent) for proper paravirtualized devices and clean shutdown/metadata.
Storage Flows with CDI
- Import: Pull a QCOW2/RAW image from a web server/registry directly into a PVC.
- Clone: Create a Data Volume from an existing PVC to duplicate golden images.
- Upload: Push a local disk image into the cluster for rapid templating.
Networking Options
- Default pod network via OVN-Kubernetes.
- Attach additional networks using Multus CNI (example: one NIC for management, one for database VLAN).
- For ultra-low-latency or NFV-style workloads, expose SR-IOV VFs with the SR-IOV Network Operator.
Scheduling, Placement & Mobility
- Use node selectors, taints/tolerations, and (anti)-affinity to spread redundant VMs across failure domains.
- Enable Live Migration for maintenance windows; remember live-migration prerequisites (shared RWX storage, adequate memory/bandwidth, and CPU compatibility if using host-model).
Day-2 Operations (What Your Team Will Actually Do)
- GitOps with Argo CD for VM YAML/templates, policies, quotas, and network attachments.
- Patch management via updated golden images (rebuild → rebase VMs).
- Observability: Use OpenShift metrics/logs; integrate with SIEM.
- Troubleshooting: virt-launcher pod contains virsh utilities; you can even instrument QEMU for deep-dive debugging when necessary.
Quick Acceptance Checklist (Per VM Class)
- Boots cleanly with VirtIO (Windows/Linux).
- Meets CPU/RAM baseline; passes latency benchmarks (if required).
- Snapshots/backup tested and documented; restore validated.
- Live-migration test (if applicable) succeeds within maintenance window.
- Network policies enforced; multiple NICs behave as designed.
Performance & Sizing
Map ESXi profiles → OpenShift VM flavors
Start by mirroring current vCPU/RAM/disk/NIC profiles as VM templates in OpenShift; validate under representative load, then right-size. Use Kubernetes requests/limits and VM CPU models carefully when targeting live-migration between hosts.
CPU, NUMA & Memory Tuning
- Prefer KVM with libvirt defaults, then tune for latency-sensitive VMs: CPU pinning, topology hints, and NUMA-aware placement to avoid cross-node memory hops. HugePages can reduce TLB pressure for big in-memory workloads.
- When using host-model CPUs, ensure all nodes presenting that VM type support the same flags—otherwise migrations will be blocked.
Storage I/O
- Back VM disks with CSI that supports snapshots/clones and the access mode you need. For live migration, use RWX shared storage (e.g., NFS/cephfs-backed PVCs). Keep data disks separate from boot to simplify cloning/patching.
Networking Throughput & Latency
- Default OVN-Kubernetes is fine for most workloads; add Multus for additional NICs/VLANs. For near line-rate, use SR-IOV with the SR-IOV Network Operator to expose VFs directly to VMs.
Benchmarking Playbook
- Establish baselines (CPU/mem, fio/rados bench, netperf/iperf) on ESXi and target nodes; compare under steady-state and peak scenarios. Define acceptance gates (e.g., ±5–10% of ESXi baseline for throughput/latency) before go-live.
Day-2 Performance Hygiene
- Enforce quotas/limitRanges to prevent noisy neighbors; spread HA pairs with anti-affinity. Validate maintenance windows with live migration dry-runs.

High Availability & Disaster Recovery Patterns
HA on a Single Cluster
- Use anti-affinity/topology spread to place redundant VMs across failure domains (racks/zones).
- Enable live migration for node drains; prerequisites include RWX shared storage, sufficient RAM/bandwidth, and compatible CPU models. Live-migration traffic is TLS-encrypted by default.
Backup & Restore Strategies
- Image-level protection via CSI snapshots/clones (then offload to your backup platform).
- App-aware backups for databases where consistency matters.
- Validate restore and document RPO/RTO; store runbooks in Git with change history.
DR Patterns
- Maintain a second OpenShift cluster; replicate storage or rehydrate from backups at DR.
- Pre-create network attachments (Multus/SR-IOV) and firewall objects; keep them version-controlled to accelerate failover.
- Rehearse DR: cold/warm start playbooks, DNS/GSLB cutover, and application health checks retain evidence for audits.
Mobility & Maintenance
- Standardize on shared RWX backends so live migrations and evacuation workflows remain predictable during patching. Track CPU model compatibility to avoid migration failures.
Security & Compliance
Identity & Access
- Enforce SSO (IdP) with groups → RBAC roles for platform team, security, app owners.
- Separate build vs run responsibilities; use least privilege and short-lived tokens.
Network & Data Protection
- Network Policies for micro-segmentation; layer egress policies for external calls.
- TLS in transit; encrypt sensitive PVCs at rest (provider capability) and protect secrets with KMS integration.
- Use image/template signing and admission controls for provenance.
Compliance Mappings
- PDPL / NCA ECC / SAMA: map controls to OpenShift constructs (RBAC, audit logs, backup/restore evidence, change management, DR drills).
- Keep an Evidence Pack: Git change records, CI/CD logs, vulnerability reports, backup & DR rehearsal minutes, SIEM exports, access reviews.
Operational Governance
- Implement policy as code (Gatekeeper/Kyverno) to enforce tagging, resource quotas, and security baselines.
- Quarterly access reviews; monthly patch windows; documented exception handling.

Day-2 Operations & Platform Engineering
GitOps for Everything (VMs too)
- Store VM templates, Network Attachment Definitions, Resource Quotas, and policies in Git.
- Use Argo CD apps per tenant/namespace; promote via environments (dev → stage → prod).
Patch & Golden Images
- Maintain golden images for Windows/Linux; refresh on Patch Tuesday / monthly Linux patch cycle.
- For running VMs, schedule maintenance windows (live-migrate → rebase/replace → verify → close).
Observability: Metrics, Logs, Traces
- Expose VM metrics (CPU steal, ballooning, I/O) next to pod metrics.
- Centralize logs; forward to SIEM with security use-cases (e.g., failed logins, config drift).
- SLOs per app; integrate alerts with runbooks.
FinOps Guardrails
- LimitRanges/Quotas per namespace; right-size templates; cleanup orphaned PVCs/snapshots.
- Tag workloads by owner/cost-center; export usage for showback/chargeback.
Reliability Hygiene
- Anti-affinity for HA pairs; Pod Disruption Budgets equivalents via planned VM migration windows.
- Pre-flight checks before upgrades; practice rollbacks.
Migration Paths from VMware
Discovery & Assessment
- Inventory VMs (CPU/RAM/disk), OS/version, dependencies, network/firewall rules, backup method, DR posture.
- Classify by risk/criticality and choose candidates for pilot.
Pilot Success Criteria
- Performance ≈ baseline (define gates, e.g., within ±10%).
- Backup/restore works (file- and image-level) and documented RPO/RTO.
- Security controls (RBAC, Net Policies, TLS, SIEM) verified.
- Change/rollback rehearsed.
Wave-Based Cutovers
- Wave 0: non-prod + low-risk.
- Wave 1–N: medium → high criticality, maintenance windows aligned to business calendars.
- Rollback playbook: time-boxed tests, objective cutover criteria, re-route/DNS steps, and clear abort conditions.
Tooling
- Use Migration Toolkit for Virtualization (MTV) (a.k.a. Forklift) for vSphere discovery, mapping (networks/storage), and orchestration into OpenShift Virtualization.
- Capture lessons & update templates each wave.
Modernize Selectively
- Containerize stateless and well-understood services first; keep proprietary/complex workloads as VMs until ROI is clear.
- Adopt API gateways, service mesh, and DBaaS patterns as you refactor.
Feature Comparison & When to Use What
OpenShift Virtualization vs vSphere
- Strengths: Unified platform for VMs+containers, GitOps/policy consistency, K8s-native operations.
- Trade-offs: Niche vSphere-specific features/plugins may require redesign or alternative tooling.

OpenShift Virtualization vs Harvester/Proxmox/Nutanix/Hyper-V
- Harvester: Also KubeVirt-based; OpenShift typically leads on enterprise ecosystem, support lifecycle, and app platform maturity.
- Proxmox/XCP-ng: Great for cost control; less opinionated around K8s-native GitOps/policy.
- Nutanix AHV / Hyper-V & Azure Stack HCI: Strong VM stacks; less seamless K8s co-existence out-of-the-box versus OpenShift’s integrated approach.
- Use OpenShift Virtualization when the destination state is Kubernetes-first and you want one control plane.
Anti-Patterns & Limits
- Ultra-niche hardware acceleration needs without SR-IOV/GPU enablement.
- Hard reliance on vSphere-only network/security plugins.
- Teams not ready to adopt GitOps/Policy-as-Code (plan enablement first).
Cost & TCO Considerations
Drivers
- Licensing & support (platform + add-ons).
- Infra (compute/storage/network), particularly shared RWX for live migration.
- Ops (automation level, toil reduction via GitOps & policy).
- Skills (enablement for platform, SRE, security, app teams).
Quick Win Areas
- Consolidate monitoring/backup/security agents; remove duplicate stacks.
- Standardize VM flavors; right-size after pilot results.
- Automate golden image pipeline and namespace blueprints to cut provisioning effort.
3-Year Model Tips
- Model current VMware run-rate vs. target OpenShift run-rate including enablement.
- Include migration project cost but also avoidance (renewals, lock-in, overlapping tools).
- Add sensitivity bands (±15%) for infra and skills ramp.
Conclusion
OpenShift Virtualization gives you one platform for two worlds: VMs that must stay put today and containers you’re ready to modernize tomorrow. By extending Kubernetes with KubeVirt, you keep governance, security, GitOps, and observability consistent across everything while avoiding a risky big-bang switch. The path is staged, measurable, and reversible: discover, pilot, move in waves with rollback, and improve.
If you’re exiting VMware, this approach is pragmatic. You preserve uptime, prove performance with clear acceptance gates, and meet compliance with audit-ready evidence (RBAC, logging, backups, DR drills). Where deeper performance is needed, features like SR-IOV, CPU pinning, and RWX storage keep latency in check and maintenance predictable with live migration.
Keep the momentum tight and focused:
- Start with a small, representative pilot and define pass/fail gates.
- Standardize VM templates, networks, and storage classes in Git.
- Plan wave-based cutovers with a rehearsed rollback.
- Lock in Day-2 ops: golden images, quotas, SIEM, and monthly patch windows.
- Capture evidence continuously to satisfy audits and regulators.
When done this way, OpenShift becomes your steady bridge cutting cost and complexity while giving teams a modern platform they can trust.



Pingback: VMware vs OpenShift Cost: TCO Model & Assumptions