
Introduction: Migration of Vmware to OpenShift
Enterprises are rethinking platform strategy, and VMware to OpenShift Migration is emerging as a practical path to lower costs, increase agility, and modernize without disruption. Rising VMware licensing complexity and budget pressure collide with the need to ship faster and standardize operations. Meanwhile, application portfolios are mixed—some workloads must remain as VMs for now, while others are ready to move into containers to unlock automation and portability.
Red Hat OpenShift provides a pragmatic bridge. With OpenShift Virtualization (KubeVirt), you can run VMs and containers side by side under one control plane, applying consistent security, policy, and automation to both. That means you can keep mission-critical VMs online while gradually refactoring candidates into containers—on your timeline.
This guide walks you through a proven, low-risk sequence: discovery and assessment, a non-prod pilot to validate performance, security, and compliance, wave-based migration with repeatable cutover/rollback playbooks, co-existence for stability, and finally optimize & scale with GitOps, CI/CD, observability, and evidence-driven compliance. By the end, you’ll have a clear template to execute VMware to OpenShift Migration with confidence—and a working VMware exit strategy you can present to stakeholders.
TL;DR
- Rising VMware costs/licensing + agility needs are driving platform rethinks.
- OpenShift lets you run VMs and containers together with one control plane.
- Start with discovery → non-prod pilot → wave-based migration.
- Keep co-existence to reduce risk; modernize in stages.
- Automate with GitOps, strengthen security/compliance, and scale efficiently.
Why Consider Migrating from VMware to OpenShift?
1)Rising Vmware Costs & Licensing Complexity
- Budget predictability: Many teams face unpredictable renewals, add-on SKUs, and per-CPU/core constraints that complicate planning.
- Consolidation pressure: As estates grow, stacking hypervisor, backup, DR, and security tools multiplies total cost of ownership (TCO).
- Ops overhead: Separate toolchains for VMs and containers increase toil, audits, and skill fragmentation.
Outcome you want: Fewer moving parts, simpler licensing posture, and clearer multi-year TCO.
2) Openshift Advantage: One Platform for VMs and Containers
- OpenShift Virtualization (KubeVirt): Run existing VMs alongside containers with a unified scheduler, networking, storage, and policy.
- Modernize at your pace: Keep critical VMs “as-is” while containerizing candidates over time—no big-bang rewrite.
- Consistent Day-2 ops: Patching, scaling, policy-as-code, GitOps, and observability apply uniformly across VMs and containers.
- Ecosystem & portability: Standard Kubernetes APIs reduce lock-in and improve mobility across on-prem and cloud.
Outcome you want: A single control plane that lowers complexity today and enables modernization tomorrow.
3) Compliance, Governance, and Future-Ready Operations
- Built-in guardrails: Role-based access control, image signing, policies, and admission controls to enforce least privilege and golden baselines.
- Auditability: GitOps and declarative configs create auditable trails (who changed what, when, and why).
- Security by design: Segmented networks, secrets management, and supply-chain controls reduce risk surface across both VM and container estates.
- Cloud-smart posture: Automation, self-service, and API-first operations accelerate change while maintaining traceability.
Outcome you want: Easier audits, stronger security posture, and an operations model aligned with where your apps are headed.

Step 1 — Discovery & Assessment
Objective
Build a single source of truth for your VMware estate—what runs where, how critical it is, what it talks to, and what will break if you move it. This turns migration choices from guesswork into data-driven decisions.
What to inventory (Minimum Viable Dataset)
- Workload identity: App name, owner, business unit, environment (prod/non-prod).
- VM specs & usage: vCPU, RAM, disk, IOPS, throughput, CPU/RAM peaks (90-day).
- Platform & OS: Guest OS/version, hypervisor tools, drivers, kernel features.
- Integrations & dependencies: DBs, queues, APIs, file shares, identity (AD/LDAP), SMTP, DNS, NTP, external SaaS.
- Network: VLAN/subnet, IPs, ports, east–west flows, egress destinations.
- Storage: Backend type (NFS/Block/Obj), capacity, performance class, snapshots/retention.
- Operational hooks: Backup/DR, monitoring, logging, patching, change windows.
- Compliance & data class: PII/financial/regulated, residency, encryption needs.
- Lifecycle signals: Owner availability, update cadence, tech debt notes.
Tip: Pull from vCenter exports + CMDB + APM/flow tools (e.g., application maps) and reconcile with app owners in a short “data validation” workshop.
Map dependencies (Don’t Skip)
- North–south: User entry, load balancers, public endpoints.
- East–west: App → DB, app ↔ app, batch jobs, message buses.
- Operational: Backup servers, SIEM, secrets, container registries.
- Change hazards: Hard-coded IPs, legacy drivers, kernel modules, shared file mounts.
Deliverable: a current-state topology (per app) and a shared services heatmap (what many apps rely on).
Business Criticality & Impact Tiers
- Tier 0: Safety/regulatory or revenue-stopping (minutes of downtime matter).
- Tier 1: Customer-facing / core ops (short outages acceptable).
- Tier 2: Internal support systems (planned downtime ok).
- Tier 3: Non-prod, labs, analytics (best pilot candidates).
Capture RPO/RTO, maintenance windows, and blackout periods for each.
Technical Fit Scoring (0–3 Per Dimension)
- Compute/Performance: Headroom, burst patterns, CPU pinning/NUMA needs.
- OS/Kernel features: Drivers/modules required, device passthrough.
- Storage: Latency/IOPS sensitivity, snapshot/clone needs.
- Network: Multicast, L2/L3 constraints, fixed IPs, firewall rules complexity.
- Operational: Backup, monitoring, patching maturity.
- Compliance/Risk: Data class, residency, encryption, audit requirements.
Sum to a Migration Complexity Score (low/medium/high) to guide wave planning.
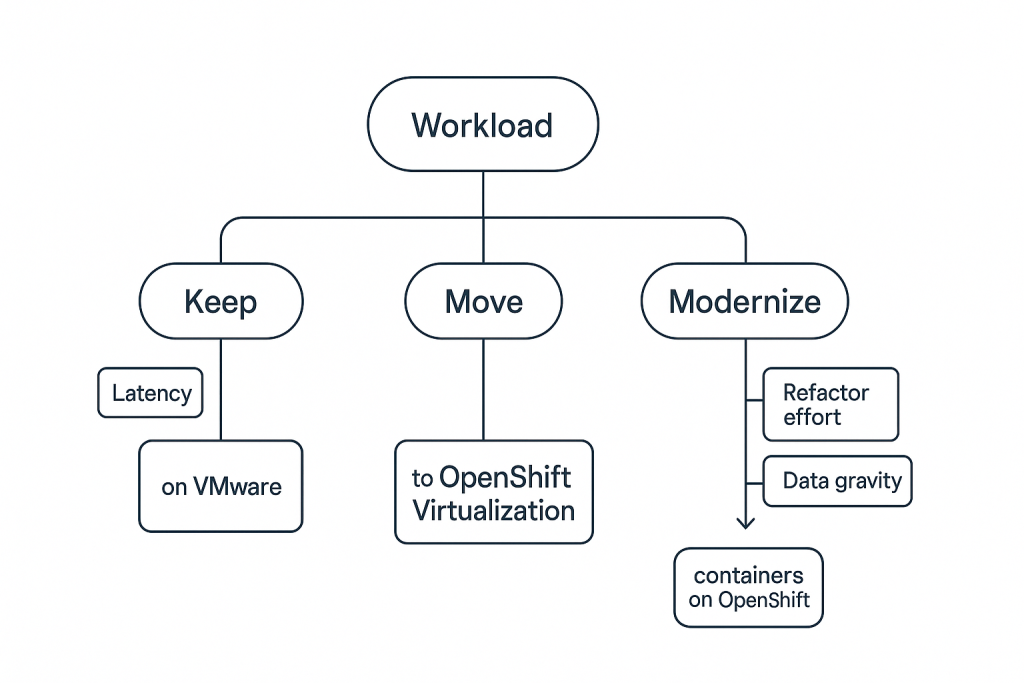
Classify: Keep / Move / Modernize
Use the inventory + scores to place each app in one bucket:
- Keep (on VMware for now)
Criteria: Tier 0, niche hypervisor features, near-term freeze, vendor support constraints.
Action: Stabilize, create exit pre-reqs (driver/app upgrades), re-evaluate in 90–120 days. - Move (lift & shift to OpenShift Virtualization)
Criteria: Compatible OS, manageable performance, limited hypervisor dependencies, medium/low criticality.
Action: Migrate VM-as-VM to OpenShift Virtualization (KubeVirt); preserve IPs/DNS where possible. - Modernize (refactor to containers on OpenShift)
Criteria: Stateless services, 12-factor-ish patterns, CI/CD-ready, scaling needs.
Action: Containerize, add Helm/Operators, implement GitOps, externalize state.
Decision Guardrails (Quick Rules of Thumb)
- If Tier 3 + low complexity → Pilot now (non-prod first).
- If needs kernel modules not supported → Keep or upgrade then Move.
- If DB is latency-critical but app is container-friendly → Modernize app, keep DB VM (co-existence).
- If audit pressure is high → Prioritize Move to standardize policy/attestation quickly.
Outputs You Should Have at the End of Step 1
- Application registry (CSV/Sheet) with the fields above.
- Dependency map per critical app + shared services heatmap.
- Criticality & complexity scores per app.
- Initial wave tags (Pilot, Wave 1, Wave 2, Backlog).
- Bucket assignment: Keep / Move / Modernize with one-line rationale.
Lightweight Worksheet (Copy/Paste Fields)
App | Owner | Env | Tier | vCPU/RAM/Disk | Peak CPU/RAM/IOPS | OS | Dependencies | Ports | Storage | Network notes | Backup/DR | Compliance | RPO/RTO | Complexity (0–18) | Bucket (K/Mo/Mod) | Wave | Notes
Step 2 — Pilot & Proof of Concept
Objective
Prove that OpenShift Virtualization can run your selected non-critical workloads reliably and securely—before you scale. The pilot should validate performance, security, and compliance with clear pass/fail criteria.
Scope & Candidate Selection
Pick 3–5 low-risk apps from Step 1 with:
- Tier 2–3 criticality (non-prod preferred).
- Few external dependencies (or easily mocked).
- OS/drivers compatible with KubeVirt.
- Clean backup/restore runbooks.
Avoid: kernel/driver edge cases, strict latency DBs, or hard-coded IPs on Wave 0.
Pilot Environment
- Cluster: 3+ worker nodes (prod-like instance types) with CPU/RAM headroom.
- Storage: CSI-backed block for VMs; snapshot/clone enabled.
- Network: L3 with required ports; egress to shared services; test Ingress/LoadBalancer.
- Tooling: Git repo for IaC/GitOps, CI for image builds, monitoring (Prometheus), logs to SIEM.
Entry Criteria
- Inventory complete for chosen apps.
- Terraform/Ansible (or equivalent) to provision pilot infra.
- Security baseline defined (RBAC, namespaces, network policy).
- Test plan and rollback steps documented.
Exit / Success Criteria (Define Upfront)
- Performance: ≤10–15% variance vs VMware baseline on CPU, latency, IOPS, p95 response times.
- Reliability: No critical incidents over a 7–14 day soak; successful node drain/eviction tests.
- Security: RBAC, image signing, secrets management, and network policies enforced; vulnerability scans clean for sev-high.
- Compliance/Audit: Change history via GitOps; logs/events in SIEM; backup/restore proven; evidence pack compiled.
- Ops: Backup success ≥99%; Day-2 ops (patch, scale, restart) executed via documented runbooks.
Test Plan (What to Actually Run)
1) Functional & Cutover
- VM import/migration to OpenShift Virtualization.
- DNS/IP strategy validated (same or new).
- Health checks, startup/shutdown, and fail/rollback test.
2) Performance Benchmarks
- Baseline in VMware → run same load in OpenShift.
- Measure: CPU, memory, disk IOPS/latency, p95/p99 API latency, throughput.
- Run under peak + 20% to test headroom.
3) Resilience & Operations
- Node drain and VM live-migration (where supported).
- Backup → restore (file-level + full VM).
- Rolling updates via GitOps; config drift detection.
4) Security Controls
- Namespace isolation; NetworkPolicies (east-west).
- Secrets in KMS/HSM-backed store; rotation test.
- Image/VM template provenance (signing/attestation).
- Vulnerability scan pipeline gate (break on sev-high).
5) Compliance & Auditability
- Log forwarding to SIEM with correlation IDs.
- Evidence pack: architecture, configs, RBAC matrix, pipeline logs, change history, backup reports, test results.
Guardrails & Rollback
- Timeboxed change windows; traffic held behind feature flags or LB weights.
- One-click rollback: revert to VMware using snapshot + DNS cutback.
- Freeze rules: no scope creep during pilot; changes via PR only.
Roles & RACI (Sample)
- Pilot Lead (Platform): owns plan, results, go/no-go.
- App Owner(s): validate functionality, sign off.
- Security/GRC: review controls, evidence pack.
- SRE/Ops: monitoring, backup/restore, runbooks.
- Network/Storage: policies, performance tuning.
30-Day Pilot Timeline (example)
- Week 1: Env build, baselines, security policies, import first VM.
- Week 2: Performance & resilience tests, fix deltas, add 1–2 more apps.
- Week 3: Security/compliance validation, backup/restore, GitOps drills.
- Week 4: Soak test, finalize evidence pack, TCO/ops findings, go/no-go.
Deliverables
- Pilot runbook & IaC repos (reusable).
- Benchmark report (VMware vs OpenShift deltas + tuning notes).
- Security & compliance evidence pack (RBAC, policies, logs, scans, backups).
- Go/No-Go memo with risks, mitigations, and wave recommendations.
Common Risks → Mitigations
- I/O variance: Tune CPU/memory requests; storage class choice; virtio drivers.
- Network surprises: Map east-west flows; apply NetworkPolicies incrementally.
- Hidden dependencies: Traffic mirroring or mocks; phased cutover.
- Skills gap: Pair platform team with app owners; short enablement sessions.

Step 3 — Wave-Based Migration
Objective
Move from pilot to predictable 30/60/90-day waves that deliver value continuously, reduce risk, and build repeatable muscle memory across teams.
Plan Your Waves (30/60/90 Cadence)
- Wave 0 (2–4 weeks): “Pathfinder” apps from pilot. Harden runbooks, finalize patterns.
- Wave 1 (30 days): 10–20% of estate — Tier 2–3, low/medium complexity.
- Wave 2 (60 days): 30–40% — add moderate dependencies and first Tier-1 non-customer-facing.
- Wave 3 (90 days): Remaining apps — higher complexity, regulated data, or seasonal load.
- Rolling backlog: Items blocked by upgrades/licensing/vendor certs; re-score every 30 days.
Wave composition rule of thumb: 60% “easy”, 30% “medium”, 10% “hard”; keep a slack buffer (10–15%) for surprises.
Readiness Gates (Must Pass Before Entering a Wave)
- Inventory complete & validated (from Step 1).
- Runbooks approved (backup/restore, cutover, rollback).
- Security baseline enforced (RBAC, NetworkPolicy, secrets).
- Performance baselines & SLOs captured.
- Change window secured + stakeholder comms scheduled.
- Data migration approach selected (snap/replicate/ETL) and tested.
Automation & Tooling
- Provisioning: Terraform + Ansible for clusters, namespaces, quotas, StorageClass, NetworkPolicy.
- VM migration: OpenShift Virtualization (KubeVirt) with virt-ctl/virt-importer; use golden VM templates.
- Containerized apps: CI builds → Helm/Operators → Argo CD/GitOps for declarative deploys.
- Data: Storage-level replication or backup tools (e.g., snapshots, Velero-style workflows) for cutover syncs.
- Observability: Prometheus/Alertmanager + log shipping to SIEM; dashboard per wave.
- Security gates: Image/VM template signing, vulnerability scans with PR blockers, policy-as-code (OPA/Gatekeeper).
Principle: Everything as Code (infra, policies, pipelines). No manual steps without a tracked exception.
Cutover Strategies (Choose Per App)
- Blue/Green (preferred for web/API): Pre-warm target → flip DNS/LB; keep blue for fallback.
- Canary (services with traffic shaping): 5% → 25% → 50% → 100% with automated health checks.
- Cold cutover (back-office/batch): Freeze writes → final sync → bring-up → validation.
- Live migration (select VMs): Where supported, test thoroughly and keep rollback snapshot.
Rollback plan every time: DNS/LB re-point, revert to last good snapshot, restore from backup, automated config rollback via Git.
Standard Wave Playbook (Rinse & Repeat)
- T-14 to T-7: Final dependency check, DR test on target, pre-prod validation.
- T-3: Freeze window starts; last data sync rehearsal; comms to stakeholders.
- T-0 (cutover): Execute playbook; real-time metrics watch; run smoke tests (functional + perf).
- T+1 to T+7 (soak): Heightened monitoring; fix deltas; confirm backups; handover to ops.
- T+14: Post-mortem/retrospective; update templates/runbooks; feed metrics to next wave.
Example 60-Day Wave Plan (Snapshot)
- Scope: 25 apps (18 Move, 7 Modernize).
- KPIs: Zero Sev-1 incidents; ≤15% perf variance vs baseline; 100% evidence packs; ≤2h mean time to rollback (if needed).
- Resources: 1 Wave Lead, 2 Platform Eng, 1 Net, 1 Storage, 1 Sec/GRC, 3 App Owners.
- Slack buffer: 3 apps for risk absorption.
Communication & Governance
- Weekly control call: Risks, blockers, burn-down (apps migrated vs plan).
- Change board approvals: Pre-approved templates reduce friction.
- Stakeholder updates: T-3 and T+1 summaries with business language (no YAML dumps).
- Evidence pack per app: Architecture, configs, RBAC, test results, backup reports, change logs.
Risk Register (Common Issues → Mitigations)
- I/O performance dips: Tune requests/limits, storage class, virtio drivers, CPU manager policy.
- Hidden East-West flows: Flow logs + temporary permissive policy → tighten post-cutover.
- Hard-coded IPs: Introduce service discovery/DNS; use static IP pools if required.
- Vendor licensing traps: Engage vendors early; document platform changes and support stance.
- Skills bottleneck: Pairing, office-hours, short enablement bursts per wave.
What “good” Looks Like
- Predictable throughput (apps migrated per week) and quality (incidents per cutover trending down).
- Reuse of golden patterns (templates, Helm charts, NetworkPolicies).
- Short MTTR/rollback and clean audit trails via GitOps and SIEM.
- Business-visible outcomes: reduced TCO, faster change lead time, improved compliance posture.
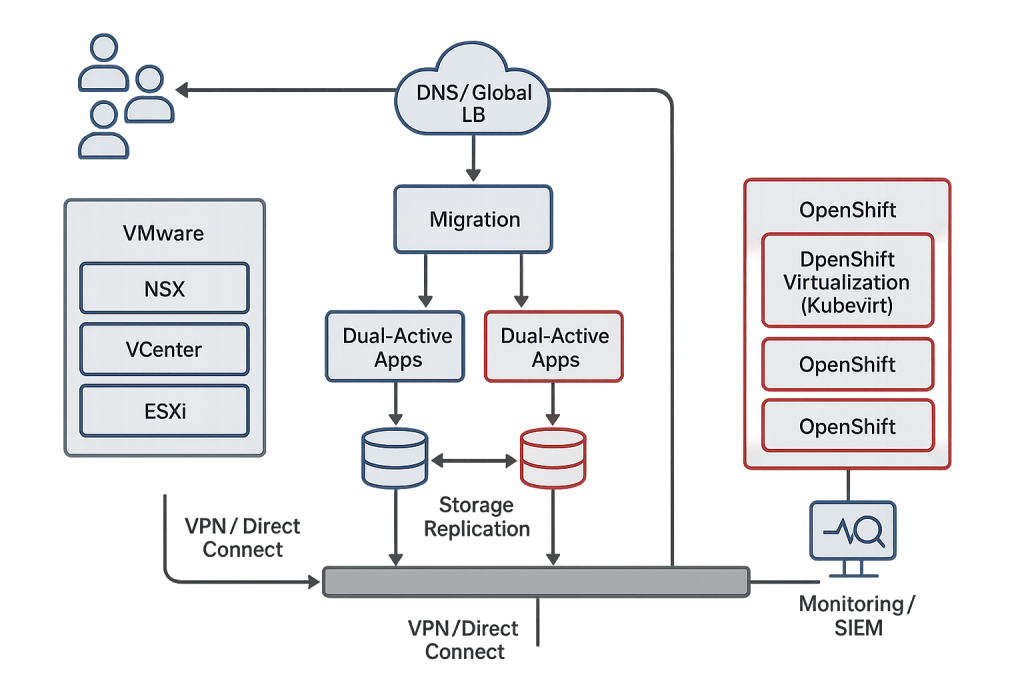
Step 4 — Co-Existence & Hybrid Operations
Objective
Operate VMware and OpenShift side-by-side so teams can migrate at a controlled pace, keep critical services stable, and modernize where it makes sense—without business disruption.
Reference Operating Model (What Runs Where)
- Keep on VMware (for now): Tier-0/Tier-1 systems with niche hypervisor features, vendor lock, or pending upgrades.
- Run on OpenShift (now): Net-new services, refactored apps, APIs, batch/worker tiers, and VMs that passed pilot tests.
- Shared services (cross-platform): Identity (AD/LDAP/SSO), PKI/KMS, DNS, SMTP, NTP, artifact/registry, logging/SIEM, secrets.
Architecture Patterns for Clean Co-Existence
- Network:
- L3 routing between platforms; explicit NetworkPolicies on OpenShift.
- Service discovery via DNS records/short TTLs; avoid hard-coded IPs.
- Layered ingress: LB/WAF → OpenShift Routes/Ingress; LB → VMware VIPs.
- Identity & access:
- One IdP/SSO (OAuth/OIDC/SAML) for both stacks; RBAC mapped to the same roles.
- Just-enough-admin on both sides; privileged actions via break-glass accounts.
- Storage & data:
- Define system-of-record per dataset; replicate to the other side as read-only where possible.
- Choose per app: storage-level replication (snapshots), DB-native replication, or ETL.
- Standardize backup tooling/retention; cross-restore drills quarterly.
- Observability:
- Unified dashboards: app SLOs (latency, errors, saturation) span both platforms.
- Logs to one SIEM with platform tags (platform=vmware|openshift).
- Golden alerts shared with on-call regardless of platform.
- Security & compliance:
- Policy-as-code everywhere (OPA/Gatekeeper on OpenShift; equivalent controls on VMware).
- Artifact/VM image signing; provenance reports included in evidence packs.
- Encrypt in transit (mTLS/TLS) and at rest; key custody via central KMS/HSM.
Traffic & Cutover Strategies in Hybrid
- Strangler pattern: New features land on OpenShift; gradually route path-by-path from legacy endpoints.
- Weighted load balancing: Shift 10%→25%→50%→100% over days; automatic health checks.
- Event-driven integration: Use queues/streams to decouple old/new components during the transition.
Day-2 Operations Playbook (Both Sides)
- Change mgmt: GitOps for OpenShift; scripted/templated changes on VMware with change tickets referencing PRs.
- Backups/DR: Common RPO/RTO targets; quarterly cross-platform restore drills.
- Patch cadence: Monthly security patch windows; emergency fix window (48–72h).
- Capacity mgmt: Right-size VMware clusters as workloads exit; autoscaling on OpenShift for bursty tiers.
- Cost controls: Tagging/labels (owner, env, cost_center, platform) + monthly showback.
Co-Existence Guardrails (To Avoid Chaos)
- One authoritative CMDB/app registry that lists platform, endpoints, data owners, and RPO/RTO.
- No dual write without idempotent design or transactional outbox patterns.
- Every app has an approved rollback: DNS flip back, snapshot restore, Git revert.
- Freeze windows respected for peak season; migrations scheduled around them.
- Golden baselines: VM templates and container base images scanned and signed.
KPIs to Know it’s Working
- Change lead time: ↓ vs baseline.
- Incident rate per cutover: trending ↓ wave-over-wave.
- Rollback MTTR: ≤2 hours.
- Audit readiness: 100% apps with current evidence packs.
- Cost trend: VMware spend ↓ in proportion to migrations; OpenShift utilization ↑ without saturation.
Six-Month Hybrid Roadmap (Example)
- Months 1–2: Harden shared services, unify logging/SSO, tag everything; migrate 10–15% “Move” apps.
- Months 3–4: Introduce strangler pattern for 2–3 customer-facing apps; containerize low-hanging services.
- Months 5–6: Reduce VMware footprint (host consolidation); shift backups/DR to target patterns; prep next wave of “Modernize”.
Exit Criteria From Co-Existence
- No legacy dependencies remaining on VMware.
- Target SLOs met for 30 days on OpenShift.
- Backup/restore and DR tests passed on target.
- Security findings closed; evidence pack signed off.
- Cost & capacity updated; VMware resources reclaimed.
Step 5 — Optimize & Scale
Objective
Turn your initial migrations into a self-sustaining, high-throughput platform: everything declarative, auditable, and automated—so teams ship faster with lower risk and cleaner compliance.
1) Make Git the Control Plane
- Single source of truth: Clusters, namespaces, quotas, NetworkPolicies, RBAC, VM templates, Helm charts → all defined in Git.
- Argo CD/Flux: Declarative sync with drift detection and automated rollback.
- Env promotion flow: dev → test → stage → prod via pull requests; approvals map to RBAC.
- Change evidence: Every change has a PR, reviewer, artifact digest, and pipeline logs (your audit trail).
Deliverables: Repo structure (platform/app), branch/PR policy, Argo projects, sync waves, drift alerts.
2) Industrialize CI/CD
- Pipelines as code: Build, test, sign, scan, SBOM, provenance attestations.
- Golden base images: Regularly patched; narrow, minimal OS; signed + pinned.
- VM lifecycle: VM templates with cloud-init, day-2 updates via Ansible/automation.
- Promotion gates: Block on sev-high vulnerabilities, failing tests, or policy violations (OPA/Gatekeeper).
Goal: Lead time ↓ 50–70%, change failure rate ↓, consistent software supply chain.
3) Platform Engineering & Self-Service
- Golden paths: Opinionated templates for “Move” (KubeVirt VM) and “Modernize” (Helm/Operator).
- Internal Developer Platform (IDP): Portal/catalog to self-provision sandboxes, DBs, and pipelines within guardrails.
- Reusable modules: Terraform/Helm modules for common stacks (API, batch, MQ, cache, DB).
- Quotas & policies: Resource limits, network egress policies, cost labels applied automatically.
Outcome: Less ticketing, faster onboarding, consistent policy enforcement.
4) Observability & SRE (Measure What Matters)
- Four golden signals: latency, traffic, errors, saturation for every service/VM.
- SLOs & error budgets: Drive release pace and rollback decisions.
- Unified telemetry: Prometheus/Alertmanager; logs to a central SIEM with platform=openshift|vmware labels; traces where useful.
- Runbooks & dashboards: Standard panels per service; on-call playbooks with “smoke tests” and rollback steps.
KPIs: p95 latency, success rate, MTTR, incidents/cutover, saturation headroom.
5) Security, Compliance & Reporting
- Policy-as-code: OPA/Gatekeeper constraints for namespaces, resource limits, egress, image registries.
- Supply-chain security: Image signing (Cosign), SBOMs, provenance (SLSA-style), registry allow-lists.
- Secrets & keys: Central KMS/HSM; rotation policies; zero plain-text secrets in Git.
- Evidence packs: Auto-generate reports per release/wave: PRs, diffs, policy checks, vulnerability scan results, backup/DR test logs.
Result: Faster audits, consistent attestation, reduced manual paperwork.
6) FinOps & Capacity Efficiency
- Right-sizing: Requests/limits tuned from actual usage; VMs and pods trimmed monthly.
- Autoscaling: HPA/VPA for apps; cluster autoscaler where appropriate.
- Cost visibility: Labels (team, env, cost_center, platform); showback per BU; anomaly alerts.
- VMware exit economics: Track host consolidation and license reductions against migration burn-down.
Targets: 20–40% infra efficiency gains over 2–3 quarters without SLO breaches.
7) Resilience & DR You Can Trust
- Backups standardized: VM images + PVC snapshots; scheduled restores validated monthly.
- DR playbooks: Cold/warm/hot patterns; quarterly game days with success criteria.
- Chaos drills (lightweight): Pod/node failures, network jitter, storage latency injection in non-prod.
Metric: Time-to-restore within RTO; data loss within RPO across both platforms.
8) Team Enablement & Operating Rhythms
- Office hours & pairing: Platform + app teams during first two quarters of scale-up.
- Brown-bag sessions: GitOps basics, debugging, on-call hygiene, security gates.
- Operations cadence: Weekly risk review; monthly cost/right-sizing; quarterly DR/chaos game day.
90-Day Optimization Plan (example)
- Days 1–30:
- Stand up Argo CD projects; enforce image signing + vuln gates.
- Instrument golden signals + SLOs for top 10 services/VMs.
- Create two golden paths (VM template, Helm app).
- Days 31–60:
- IDP portal with self-service sandboxes; cost labels mandatory.
- Tune requests/limits based on telemetry; enable HPA on 5 services.
- First evidence-pack automation (PR → PDF bundle, SIEM link).
- Days 61–90:
- Quarterly DR game day; restore proofs attached to evidence packs.
- Right-size 20% heaviest workloads; deprecate unused images/VMs.
- Wave dashboard: burn-down, incidents per cutover, perf deltas, cost trend.
What “Good at Scale” Looks Like
- Throughput: Regular waves landing without heroics.
- Quality: Incidents per cutover trending down; MTTR < 60–120 min.
- Control: 100% changes via PR; drift auto-corrected; policies enforced by code.
- Compliance: Evidence packs generated automatically; audits are routine, not fire drills.
- Economics: Measurable TCO improvement with no SLO regression.

Best Practices for VMware to OpenShift Migration
1) Align Migration with Business Priorities
- Define business outcomes first: Cost targets, agility metrics (lead time, deployment frequency), and risk thresholds (RPO/RTO).
- Score apps against value & effort: Use a simple 2×2 (business impact × migration complexity) to pick Pilot → Wave 1 → Wave 2.
- Bundle dependencies: Migrate services that talk heavily to each other in the same wave to avoid ping-pong latency.
- Protect the calendar: Respect blackout windows; reserve fixed change slots for cutovers.
- Make value visible: Track a burn-down (apps/licensing) and a burn-up (SLO stability, cost saved) so leadership sees progress.
Quick win: Start with Tier-3/Tier-2 non-prod systems that unlock reusable patterns (golden VM template, Helm chart, NetworkPolicy).
2) Focus on Security & Compliance From Day One
- Policy as code: Enforce RBAC, namespace quotas, allowed registries, and egress rules via OPA/Gatekeeper; PRs must pass these checks.
- Supply-chain security: Sign images/templates (Cosign), attach SBOMs, and block on sev-high vulnerabilities in CI.
- Secrets & keys: Centralize in KMS/HSM; rotate on schedule; forbid plaintext secrets in Git.
- Auditability: Use GitOps to create a tamper-evident change log; forward logs/events to SIEM with platform=vmware|openshift.
- Backups/DR first: Snapshot VMs/PVCs, test restores monthly, and attach results to an evidence pack (your audit artifact).
- Network segmentation: Default-deny NetworkPolicies; gradually open only required flows.
Anti-pattern to avoid: “Harden later.” Retro-fitting policy, secrets, and audit trails after waves begin multiplies risk and rework.
3) Train Teams on Kubernetes & OpenShift
- Role-based enablement:
- App teams: Pods, services, ConfigMaps/Secrets, Helm, GitOps promotion.
- Platform/SRE: Cluster ops, quotas, autoscaling, monitoring, backup/restore.
- Security/GRC: Policy-as-code, attestations, evidence-pack review.
- Golden paths: Provide starter repos (VM template and Helm app) so teams follow known-good patterns by default.
- Pairing & office hours: Stand up weekly clinics during Waves 1–2; capture FAQs into runbooks.
- Certify what matters: Short internal badges (GitOps 101, Incident Response on OpenShift, NetworkPolicy basics).
- Measure learning: Track adoption of golden paths, failed policy checks trend, and MTTR improvement as training ROI.
Tip: Treat enablement like a product — version it, gather feedback, and iterate each wave.
Guardrails & Checklists
- Pre-wave gate: Inventory ✅ | Runbooks ✅ | Security baseline ✅ | Baselines & SLOs ✅ | Data plan ✅
- Cutover kit: Rollback snapshot | DNS/LB plan | Smoke tests | Observability dashboard link | On-call roster
- Post-wave: Soak metrics | DR test proof | Evidence pack attached | Retrospective actions merged
Common Challenges and How to Overcome Them
1) Skills Gap → Training & Managed Services
Symptoms: Slow cutovers, fragile pipelines, “Kubernetes confusion,” over-reliance on a few experts.
What to do:
- Role-based enablement: Short, targeted tracks: App (Helm/GitOps), Platform (cluster ops/backup), Security (policy-as-code/attestation).
- Golden paths: Ship starter repos (VM template + Helm app) with CI, policies, and dashboards prewired.
- Office hours & pairing: Weekly clinics during Waves 1–2; pair platform with each app team for first cutover.
- Managed boost: Use a managed OpenShift or a migration partner to run pilots, harden runbooks, and coach on Day-2.
- Measure learning: Track policy-check failures ↓, MTTR ↓, % deployments via golden paths ↑.
Anti-pattern: “Train later.” You’ll pay with outages, rework, and shadow IT.
2) Complex Apps → Staged Modernization
Symptoms: Tightly coupled tiers, hard-coded IPs, shared filesystems, kernel/device dependencies, latency-sensitive DBs.
What to do:
- Decompose the risk: Move supporting tiers first (batch, workers, APIs), keep DB or stateful core on VMware initially.
- Strangler pattern: Route a subset of traffic (endpoints/paths) to OpenShift; expand as confidence grows.
- Stabilize dependencies: Introduce DNS/service discovery, externalize configs/secrets, remove IP pinning.
- Data strategy per tier:
- Read-heavy → replicate read-only.
- Write-heavy → freeze window + final sync.
- DBs → native replication/HA or keep on VMware until refactor.
- Performance hygiene: Baseline on VMware; enforce p95/p99 targets; tune CPU manager, storage class, virtio drivers on OpenShift.
Guardrail: If kernel modules/passthrough are blockers, Move as VM first (KubeVirt), Modernize later.
3) Compliance → Evidence Packs & DR Drills
Symptoms: Audit anxiety, scattered change records, unclear backup/restore proof, manual screenshots.
What to do:
- Automate evidence: From every PR/pipeline, collect artifacts: commit diff, approvers, SBOM, scan results, policy checks, Argo sync logs. Bundle into an evidence pack per app/wave.
- Policy-as-code: OPA/Gatekeeper to enforce allowed registries, resource limits, egress, and RBAC; block on sev-high vulnerabilities.
- Unified telemetry: Forward logs/events to SIEM with platform=vmware|openshift; tag releases with build SHA and ticket ID.
- Backups you can prove: Standardize VM/PVC snapshots; monthly restore drills with screenshots/logs attached to the evidence pack.
- DR you rehearse: Quarterly game days (cold/warm/hot). Success = RPO/RTO met + signed report.
Result: Audits become routine—facts in one place, traceable to code.
Quick checklist
- Skills: Golden paths ✅ | Office hours ✅ | Managed assist (pilot+wave) ✅
- Complexity: Strangler pattern ✅ | DNS/service discovery ✅ | Data plan per tier ✅
- Compliance: Policy gates ✅ | Evidence packs automated ✅ | Backup + DR drills ✅
Conclusion — Make Your VMware to OpenShift Migration a Success
A successful VMware → OpenShift journey is less about a single cutover and more about building a repeatable, low-risk operating model. You start by turning your estate into clean data (Discovery & Assessment), prove value and de-risk with a non-prod Pilot, then move steadily through 30/60/90-day waves with automation, clear cutover/rollback playbooks, and measurable SLOs. Run co-existence deliberately—keep mission-critical VMs stable while modernizing the right services on OpenShift—then optimize and scale with GitOps, CI/CD, observability, and policy-as-code so audits and releases become routine, not heroics.
Keep the compass set on business outcomes (cost, agility, risk, governance). Embed security and compliance from day one, and invest in team enablement with golden paths and pairing. When you make everything declarative infra, policies, pipelines, and evidence migration becomes predictable, auditable, and cost-effective.
If you remember one sequence:
Discover → Pilot → Waves → Co-exist → Optimize.
Do it in small, proven increments, and your organization will land a modern platform that runs VMs and containers together—safely, efficiently, and ready for what’s next.

FAQs — VMware to OpenShift Migration
Q1) Why are enterprises moving from VMware to OpenShift now?
Rising licensing costs, a push for container‑native agility, and the need to modernize apps are the big drivers. OpenShift Virtualization (KubeVirt) lets you run VMs and containers together, so you can migrate at your pace without a risky “big bang.”
Q2) Can OpenShift match VMware’s VM performance?
For most general‑purpose workloads, yes—when you size nodes properly, enable CPU/hugepages where appropriate, use optimized storage (e.g., CSI drivers with RWX/RWO fit), and keep the cluster free of noisy neighbors. Always benchmark representative workloads during the pilot.
Q3) Do we still need vSphere if we adopt OpenShift Virtualization?
Not necessarily. Many teams run VMs directly on OpenShift via KubeVirt. Some keep a minimal vSphere footprint temporarily for legacy dependencies and retire it wave‑by‑wave.
Q4) What’s the safest migration path?
Follow a 5‑step flow: Discovery & App Mapping → Pilot & Success Criteria → Wave‑based Migration (30/60/90 days) → Co‑existence (keep/move/modernize) → Optimize (GitOps, automation, observability).
Q5) How much downtime should we expect?
Plan per app. Stateless services often move with near‑zero downtime behind load balancers. Stateful apps may need maintenance windows, replication/cutover, or blue‑green patterns. Always define rollback and data‑validation steps.
Q6) How do licenses and TCO compare over 3 years?
OpenShift is subscription‑based and consolidates platform + virtualization + container orchestration + security features. Savings generally come from reduced hypervisor sprawl, improved density, and automation. Validate with a TCO model (license + infra + ops + skills).
Q7) What skills does my team need in year one?
Core Kubernetes/OpenShift ops, GitOps pipelines, policy as code, and container security basics. For VM admins, cross‑training on KubeVirt concepts (virtctl, virt‑launcher, VM templates) plus storage/backup patterns is key.
Q8) How do we handle storage, backup, and DR for VMs on OpenShift?
Use CSI‑backed storage with snapshots, define backup policies via Velero/ODF or enterprise equivalents, and design DR with asynchronous replication and runbooks. Test restores and DR drills quarterly.
Q9) What about compliance (PDPL, NCA ECC, SAMA) and data residency?
Keep workloads and data in‑country regions, enforce RBAC/SSO, encrypt data at rest/in transit, centralize logs to SIEM, and maintain change‑management evidence packs. OpenShift’s policy/guardrails and audit logs help you demonstrate controls.
Q10) Which apps should move first?
Start with non‑critical, low‑complexity services to prove performance and operations. Then move tier‑2 workloads, followed by complex/stateful systems once patterns are stable.
Q11) What tooling helps reduce risk during migration?
GitOps (Argo CD), CI/CD, image registries with signing/scanning, policy engines (OPA/Gatekeeper), observability stacks (Prometheus/Grafana/ELK), and runbooks with automated checks.
Q12) How do we measure success?
Define pilot KPIs up front: VM performance within X% of baseline, deployment time reduced by Y%, policy violations at zero, MTTR improved, and successful DR drill completion. Post‑go‑live, track cost/CPU‑mem density, change lead time, and incident rates.


Pingback: Understanding OpenShift Virtualization (KubeVirt): Key Concepts & Best Practices
Pingback: A Complete Guide to OpenShift Virtualization